When you're asked to pay $400+ a month for AEO software trackers, you'd expect to have accurate data in your console. But AI search isn't anything like SEO. The LLM platforms don't provide us with a Search Console like Google does.
So how can you still have a dashboard that tells you you're "ranking" well for a certain prompt?
The truth is, you can't.
As you're optimizing for your target AI prompts, your target customers are seeing very different results than the ones you're monitoring. This is because every response generated by AI for your customers is unique while every response generated by AI for your tracking software is boilerplate. The AI platform doesn't have any background information on the request. No context. It's beginning from a blank slate—so it will churn out blank slate results. Generic. Not personalized. Meanwhile, your customers are seeing personalized responses with URLs that are completely different from the ones you're seeing in your prompt tracking.
That means when you finally "get" a citation for a prompt you've chosen, there's little chance you're actually showing up in other results. And since it's essentially impossible to track every variation of every prompt in which your domain may show up as a citation, business owners are currently at a bit of a loss compared to the data-rich arena of Google Search.
So what are businesses left to do?
One possibility is to use ICP Framing in your prompts. That means taking a generic prompt that you might be already tracking and updating it to include information on your ICP (Ideal Customer Profile) and/or terminology that your ICP would use.
I built a 45-call "smoke test" (to borrow a term from the dev world) to figure out whether using ICP Framing in a prompt actually changes which URLs get cited in — or whether the persona language is mostly decoration around a query whose citations are determined by the content terms.
Basically I wanted to know—is this actually a problem?
Turns out it is.

The preliminary finding
The motivating question is unglamorous but consequential. Most AI-citation monitoring tools — Profound, Stacker, BrightEdge — pull citations using generic versions of the questions a brand's buyers might ask. They extrapolate and model based on samples of people that might include your ideal customer profile—and might not. So they're not giving you real-life data—they're giving you statistical estimates, and in the world of AI, that's not enough.
If the prompt "what is zero trust architecture?" produces roughly the same citation set as "as a CISO at a healthcare provider, what is zero trust architecture?", then generic monitoring (what all those tools do) is a reasonable proxy for what a specific buyer would see.
If those two sets are mostly disjoint, however, then the entire category of generic-prompt monitoring is measuring something distinct from what users actually encounter in their own sessions. The importance of this cannot be overstated. At that point, it's not a marketing problem; it's a measurement problem. And, as they say, GIGO—garbage in, garbage out.
I expected the difference to be modest.
The data was strange and compelling enough that I'm publishing the smoke test early before the larger-scale test.
Setting up the smoke test
I picked five base questions from a CISO (cybersecurity) research vocabulary — zero trust architecture, multi-factor authentication rollouts, EDR versus XDR, ransomware recovery, identity and access management tooling — and built three variants of each prompt.
- Generic Prompt: the bare question.
- "What is zero trust architecture?"
- Persona-Prefixed Prompt: the same question with a one-line persona prefix.
- "As a CISO at a mid-to-large healthcare provider (1,000–5,000 employees), what is zero trust architecture?"
- Persona-Rewritten Prompt: an LLM-reformulated version using language a healthcare CISO would plausibly type.
- "Zero trust strategies for HIPAA-bound hospital networks with legacy EHR systems."
I ran each variant through Claude's web search tool, ChatGPT's web search tool, and Perplexity Sonar — 5 questions × 3 variants × 3 engines = 45 engine calls. For each call I captured the ordered list of cited URLs.
The metric was Jaccard similarity, computed pairwise between the three variants per (question, engine) cell. Jaccard similarity is a 0-to-1 measure of overlap in results: 1.0 means there's full overlap in citation URLs between two types of prompts listed above, 0.0 means they share no URLs at all, and 0.5 means they share half their combined members.

The result
The result is striking, and it gets sharper the closer you look.
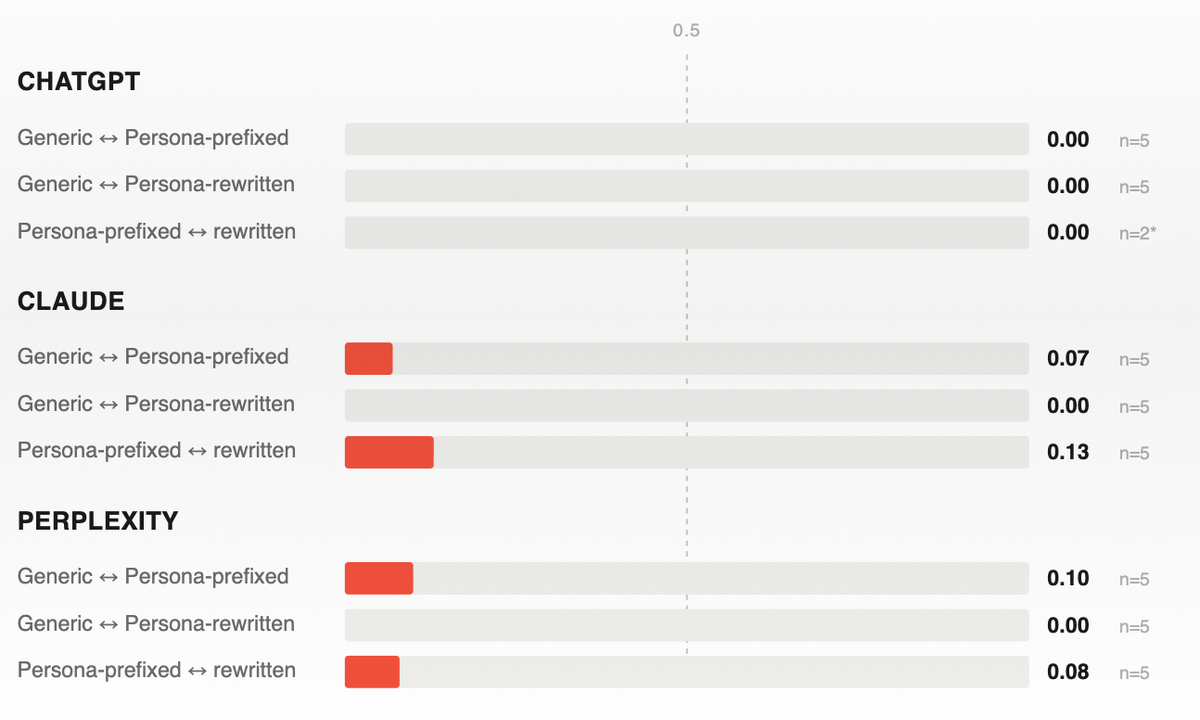
Pooled across all engines and all five questions:
| Variant pair | Mean Jaccard | n cells |
|---|---|---|
| Generic ↔ Persona-prefixed | 0.06 | 15 |
| Generic ↔ Persona-rewritten | 0.00 | 15 |
| Persona-prefixed ↔ Persona-rewritten | 0.09 | 12 |
A Jaccard of 0.06 means the two prompt variants shared, on average, 6% of their combined citations.
A Jaccard of 0.00 means they shared none at all.
Our smoke test revealed that the persona-aware versions of the same underlying question pulled citations from a fundamentally different pool than the generic baseline (middle row in the table above).
That's not a small effect. That's two parallel universes of sources for the same buyer intent.
Read that sentence twice.
If you're spending real money on AEO tooling, and that tooling polls generic prompts, ~94% of the citations it's tracking aren't the citations your buyers are seeing.
You're optimizing toward — and making decisions from — a parallel universe.

The per-engine breakdown shows the same pattern across Claude, ChatGPT, and Perplexity. Every engine that returned citations on a persona-aware prompt returned a citation set that overlapped almost nothing with the generic version of the same question. There's no engine in this batch where persona framing is "decoration." All three weight it as substantive query signal.
To make the disjointness concrete: here's a single cell from the experiment — Claude, asked "What is zero trust architecture?" in our three different prompt styles:

The generic prompt cited what an analyst would expect: NIST, CrowdStrike, Microsoft, Palo Alto Networks — the big-name cybersecurity authorities. Add a healthcare-CISO persona and the engine pivots into a completely different citation world: HIPAA blogs, healthcare IT consultancies, hospital case studies. The two universes of sources barely touch.
Of 39 distinct URLs cited across these three variants, only 4 appeared in more than one set. The remaining 35 were unique to a single variant.
ICP-based prompting is a superior way of measuring your company's citation health
If your monitoring tool is polling "what is zero trust architecture?" and your buyer is a healthcare CISO, you're tracking citations on Microsoft and CrowdStrike. Your buyer is reading citations from medicalitg.com and Cognizant's healthcare zero-trust whitepaper. Those two reports of "how am I doing in AI search" answer different questions.
The fix is not to track more generic prompts. The fix is to model your actual buyer — their role, their industry, their compliance constraints, their vocabulary — and to monitor the prompts they would actually run. Every dollar you spend tracking the generic version is a dollar measuring sources your buyer will never see.
When I release the results of the exhaustive test I'll make sure to include guidelines on what criteria a properly-phrased ICP prompt is. Be sure to subscribe to get updates when I release that.
The final word: every content recommendation that comes out of generic-prompt monitoring is a recommendation calibrated to the wrong audience. AI platforms know so much about their users that answers and citations appear differently for every person. Businesses need a way to account for that instead of continuing to believe that generic prompting will get them the data they want. It just ends up with them optimizing for all the wrong things.
"We need more sources that look like NIST" is the right advice for a generic search; it's the wrong advice when your buyer is in healthcare and the engines are citing healthcare-specific blogs to them. Acting on misaligned data doesn't just waste budget — it pulls your content strategy toward the wrong references.
My advice: check out the prompts you're tracking and determine whether they're generic or truly ICP-friendly. More to come soon on our findings at Quoted on what makes those prompts tick (and how to apply those findings to your own tracking).